Sears, R., C. Ingen, J. Gray, 2006: To BLOB or Not to BLOB: Large Object Storage in a Database or a Filesystem?, MSR-TR-2006-45
들어가기에 앞서
일반적으로 이미지나 동영상 파일을 DB에 저장할 때는, 파일은 파일시스템에 저장하고 그 링크만 DB에 저장한다(현재 부트캠프에서도 이와 같이 배웠다). 그런데, 링크만 저장할 경우에는 DB를 읽고, 그 링크에서 따로 파일을 로딩하는 로직을 따로 거쳐야 하는 코드를 작성하는 등 이중으로 로직을 작성해야 한다. 하지만, 이미지나 데이터를 DB에 바로 저장한다면 추가적인 작업이 필요가 없을텐데 라는 생각이 들어서 검색을 하게 되었다.
개발자 포럼 중 한 곳에서 DB에 이미지파일을 저장하는 방법을 다루었고, 주장에 대한 근거로 마이크로소프트 리서치에서 출판한 기술문서를 제시하였다. 본인 역시 이에 대한 의문을 갖고있었으므로, 기술문서를 읽고 정리함으로써 의문을 해소하고자 한다. 또, 논문리뷰 카테고리에 정리하였지만, 다루고자하는 문서는 일반적인 논문형태를 가지고 있지 않은 기술문서이므로 이를 감안하여 읽어야겠다.
Abstract
DB를 설계할 때, BLOB(Binary Large OBject)를 DB에 저장할 지, 아니면 파일시스템에 저장할 지를 결정하여야 한다. 전통적으로 DB는 각파일의 용량이 작고 파일의 개수가 많을 경우에 좋은 성능을 보이고, 파일시스템(본 문서에서는 NTFS)은 용량이 큰 데이터를 처리할 때 좋은 성능을 보인다. 물론 각각의 파일시스템, 데이터베이스 시스템, 워크로드에 따라 다르겠지만, 본 문서에서는 평균 256KB의 BLOB에서는 DB에 저장하는 것이 좋은 성능을 보였고, 1MB 이상의 BLOB에 대해서는 파일시스템에 좋은 성능을 보였다. 또 본 문서에서는 여러 측정지표들을 통하여 성능을 제시하였고, 이러한 내용은 아래에 기술하겠다.
1. Introduction
웹 서비스의 이용 및 네트워크를 사용하는 서비스가 증가하고 있다. 이에 따라 데이터베이스의 읽기/쓰기가 증가하게 되었다. 어플리케이션 설계자들은 BLOB를 저장 공간을 DB나 파일시스템 중에 선택하여야 하며, 전통적으로 두 방법은 tradeoff 관계에 있다고 한다. 대부분의 설계자들은 작은 파일은 DB에, 큰 파일은 파일시스템에 저장하여야 한다고 말하고 있으나, 적고 큼의 기준(break-even point)은 어떤 것인지 또 이 둘 간의 tradeoff는 정확히 어떤 것인지를 알고있지 못한다. 따라서 본 기술문서에서는 write-intensive한 웹 어플리케이션을 사용하여 비교분석을 하고자 하였다. 한가지 중요한 점은 저장공간의 단편화가 break-even point를 결정하는 큰 요인이었다고 하였다.
2.Background
2.1 Fragmentation
단편화는 파일시스템에서 저장공간을 낭비하는 이슈 중 하나로, 파일시스템은 단편화를 회피할 수 있도록 정교하게 사용되고 있다. 본 기술문서에 사용한 파일시스템인 NTFS역시 단편화를 피하기 위한 방안을 사용하고 있으나, 단편화를 피하지 못하는 경우가 발생한다고 한다. 따라서 파일 삭제시에 단편화된 공간은 그 즉시 사용하지 못한다.
데이터베이스 시스템은 전통적으로 약 100바이트 정도의 작은 양의 레코드를 저장하는 것을 목적으로 한다. 따라서 파일시스템과 데이터베이스 시스템은 다른 방법으로 레코드 혹은 데이터를 변경한다. 파일시스템의 경우에는 파일을 자르거나 혹은 이어붙이는 것에 최적화외더있다. 따라서 파일 중간을 삭제하거나 삽입하는 명령이 발생하면, 타깃 파일의 전체를 재작성한다. 하지만 SQL 서버와 같은 경우에는 BLOB를 삭제 혹은 삽입할 때 효율적으로 이루어질 수 있도록 하였고, B-Tree를 사용한다고 한다.
또한 데이터베이스 시스템은 용량이 크면서 단편화되어있는 파일을 처리하기 위해 de-fragmentation을 수행하거나 가비지 컬렉션을 수행한다고 한다. 또한 효율적인 서비스를 위해서 비디오과 같이 큰 파일은 smaller chunk로 나누어 저장하기도 하고, 이를 다시 병합하는 과정을 수행하기도 한다.
2.2 Safe write
본 기술문서는 insert, replace, delete에 관한 명령만 다룬다고 한다. 파일시스템에서 replace 명령을 수행할 때에는 파일을 먼저 새 파일을 생성하고, 그 후에 기존의 파일을 삭제한다고 한다. 또한 갑작스런 셧다운과 같은 문제가 발생할 때 메타데이터(디렉토리 구조, 파일 명 등)를 보존하기 위하여 safe write를 도입하였다고 한다. safe write는 아래와 같은 스텝으로 이루어진다고 한다.
1. 새로운 버전의 파일을 위해 임시 파일 생성
2. 임시 파일에 새로운 버전의 파일을 write.
3. 임시 파일을 디스크에 저장.
4. 임시 파일을 실제 이름으로 변경함.
5. 기존의 파일을 삭제.
반면에, 데이터베이스 시스템은 강제 셧다운이나, database crash, application crash와 같은 상황과 무관하게 트랜잭션들을 처리한다고 한다. 따라서 데이터베이스는 squential하게 로그를 저장하여 데이터베이스를 보존한다. 다만, BLOB의 경우에는 transaction을 로그에 저장한다면, 큰 성능저하가 발생한다. 따라서 본 기술문서에서는 bulk-logged라는 기능을 사용한다고 한다.
4. Comparing Files and BLOBs
본 기술문서에서는 실험을 위하여 SharePoint, Hotmailk, flickr, MSN space를 사용하였다고 한다. 이 사이트 모두 data-intensive한 웹사이트들이므로 본 기술문서에서 측정하고자 한 성능을 확인할 수 있을 것이라고 한다.
5. Result
5.1 Database or Filesystem: Throughput out-of-box

Figure 1은 데이터베이스와 파일시스템의 읽기 성능을 비교한 것이다. 비교는 clean data storage에서 비교를 수행하였다고 한다. 256KB의 파일 크기에서는 데이터베이스가 파일시스템보다 약 2배가량 높은 성능을 보였으나, 1MB 크기의 읽기에서는 두 시스템 모두 비슷한 성능을 보였다.
5.2 Database or Filesystem over time
단편화가 성능에 중요한 역할을 한다면, overwrite 시에 발생하는 단편화가 성능에 큰 영향을 미칠 것이라고 하였다. 따라서 overwrite 후에 성능을 측정하였다고 한다.


Figure 2는 2회 overwrite 및 4회 overwrite 후에 측정한 성능을 나타낸 것이다. 파일시스템의 성능저하는 크지 않은 반면에 데이터베이스의 성능저하는 크게 낮아졌다. 이는 단편화가 큰영향을 미쳤을 가능성이 크다고 한다.
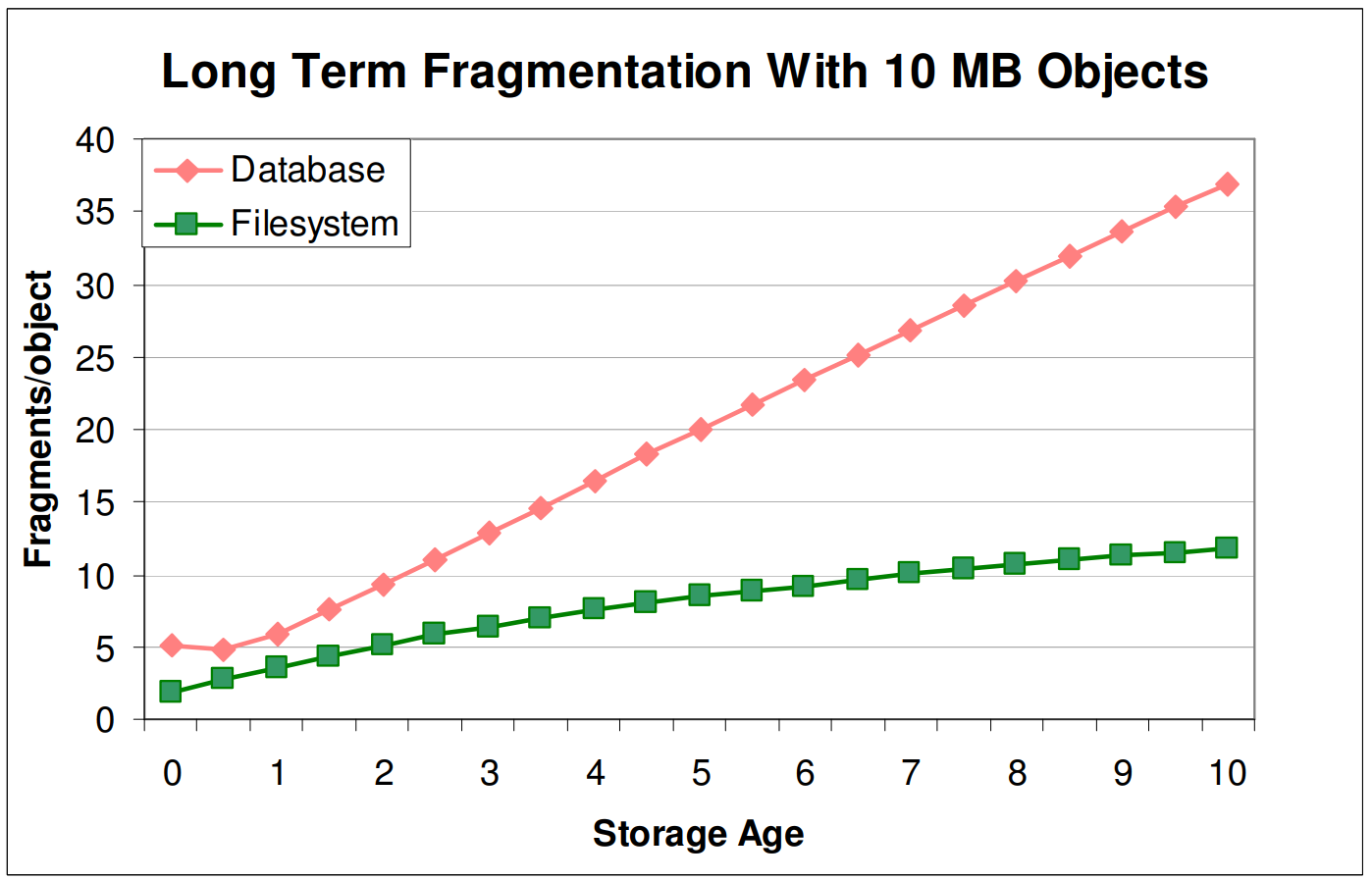
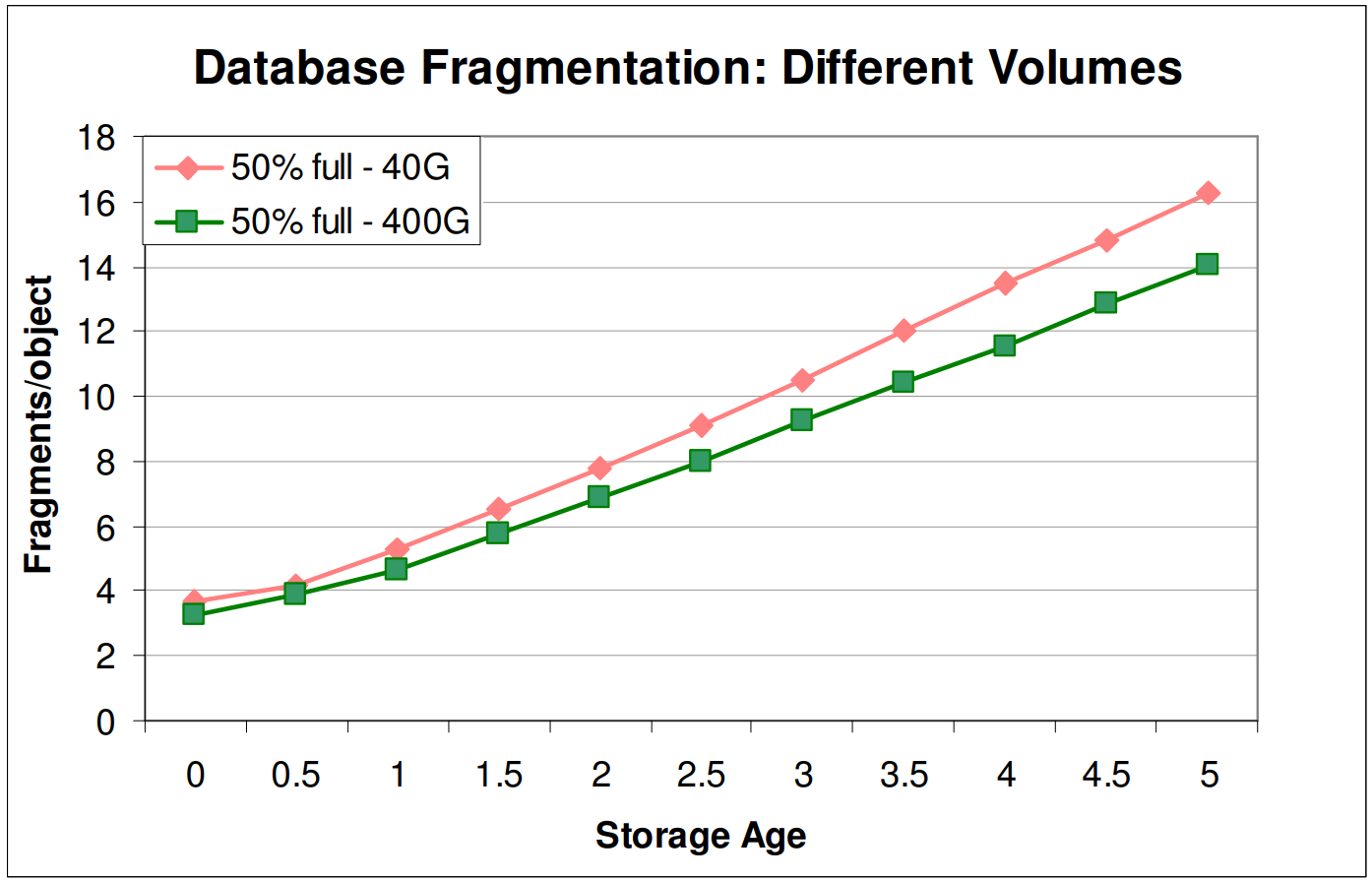
실제로 Figure 3을 살펴보면 파일시스템의 단편화는 크게 발생하지 않은 반면에 데이터베이스의 단편화는 storage age가 증가함에 따라 선형적으로 증가하는 것을 확인할 수 있다.

Figure 4는 두 시스템의 쓰기 성능을 비교한 것이다. storage age가 증가함에 따라 파일시스템은 성능 저하가 크지 않은 편인데, 데이터베이스는 성능저하가 두드러진 것을 확인할 수 있다.
따라서 이러한 결과는 아래와 같은 결과를 도출한다.
- 256KB 이하의 파일은 데이터베이스에 저장하는 것이 좋을 수 있다.
- 1MB 이상의 파일은 파일시스템에 저장하는 것이 효율적일 수 있다.
위의 주장을 뒷받침하기 위해서 256KB 사이즈의 파일들을 사용하여 storage age에 따른 fragment 정도를 확인하였다고 한다.
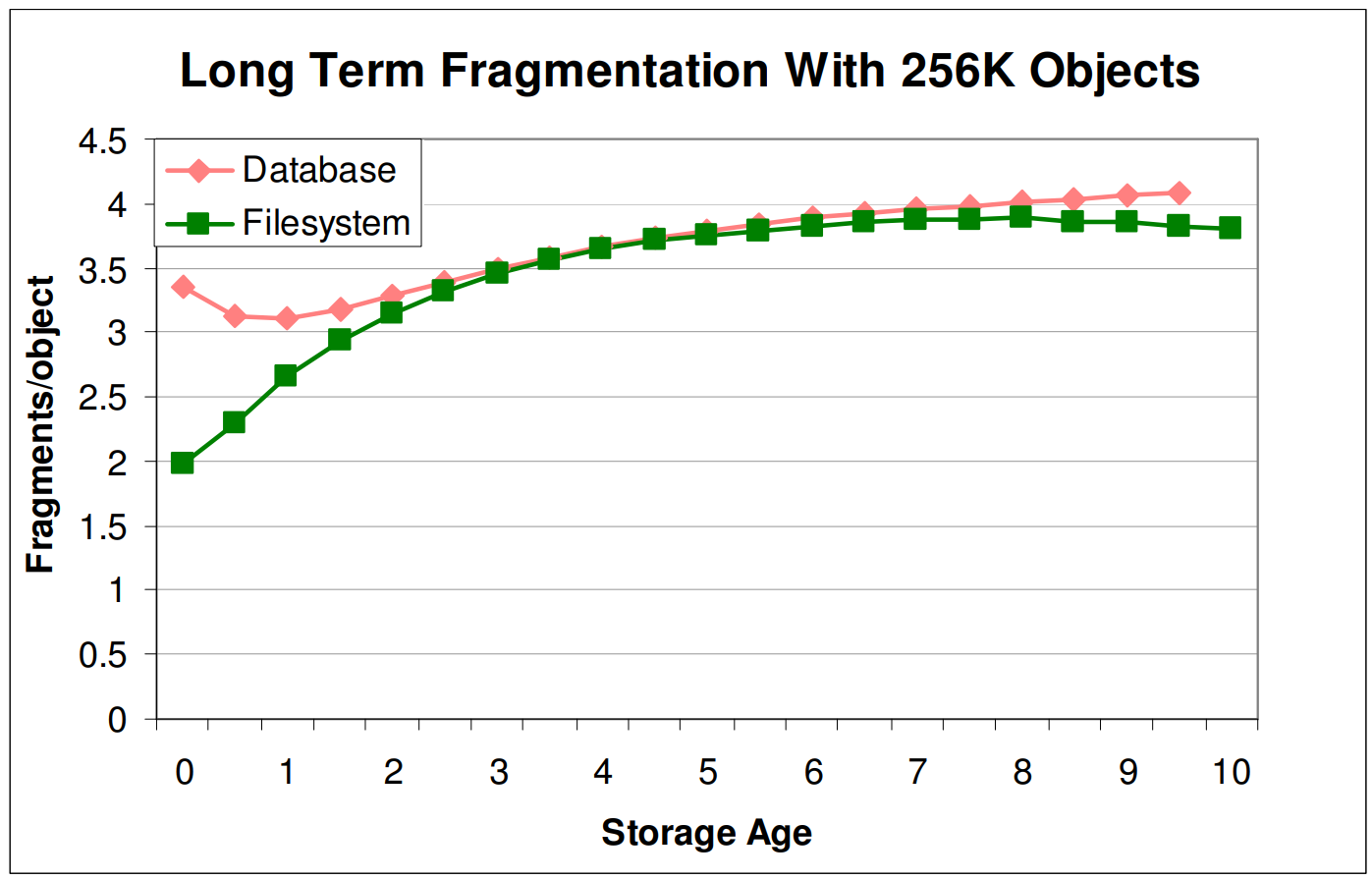
Figure 5는 위 실험의 결과인데, storage age가 지나더라도 단편화가 발생하는 양은 두 시스템 모두 비슷하였다고 한다.
5.3 Fragmentation effects of object size, volume capacity, and write request size
저자들은 동일한 사이즈의 파일을 계속 쓰기하는 것은 단편화를 불러일으킬 수 없을 것이라 기대하였지만, 이 생각은 틀렸다고 한다. 평균이 10MB이고 정규분포를 따르는 파일들을 사용하여 쓰기하는 것과, 동일한 사이즈의 파일을 쓰기하는 것에서 발생하는 단편화 양은 거의 동일하였다고 한다.
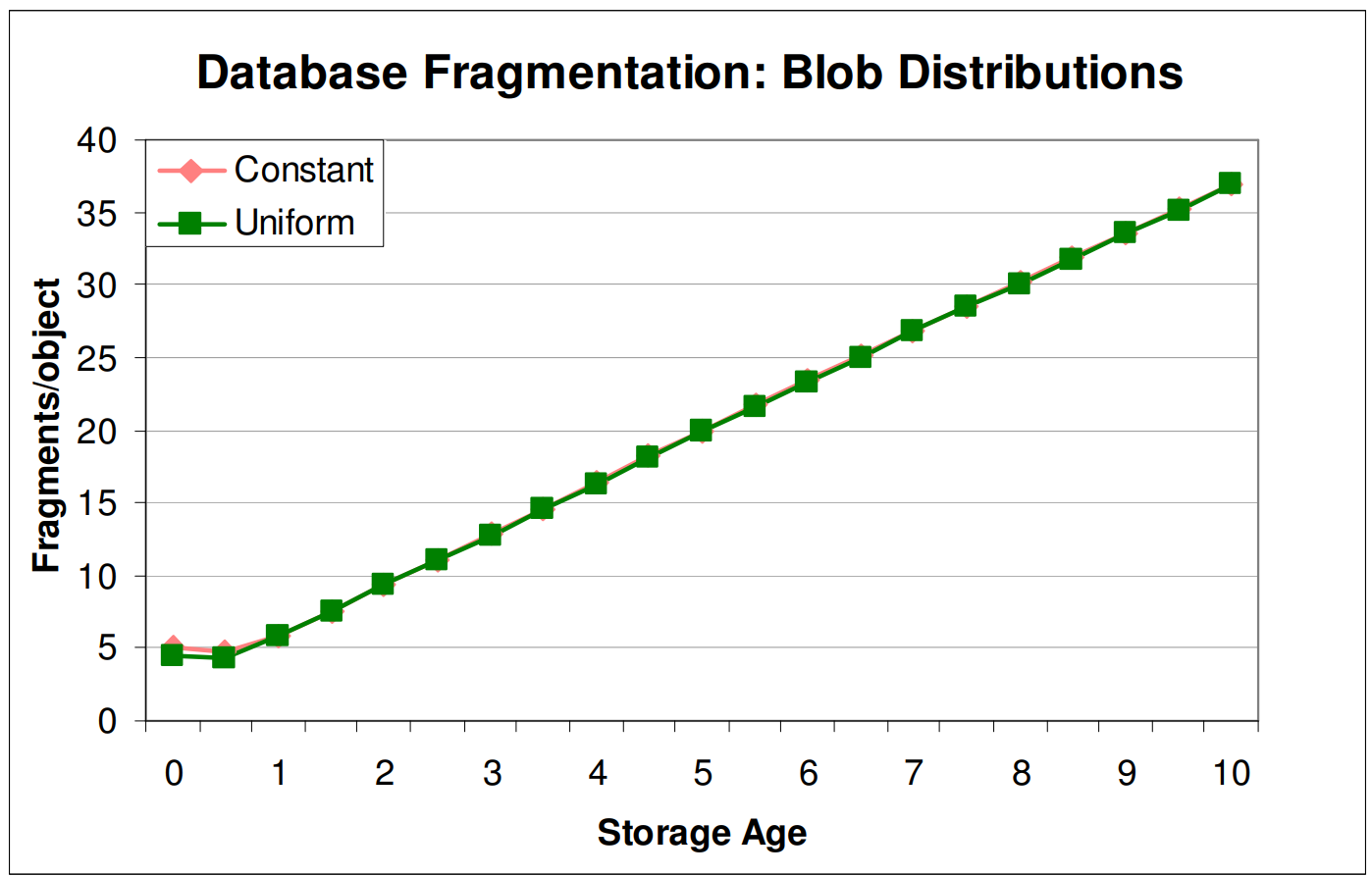
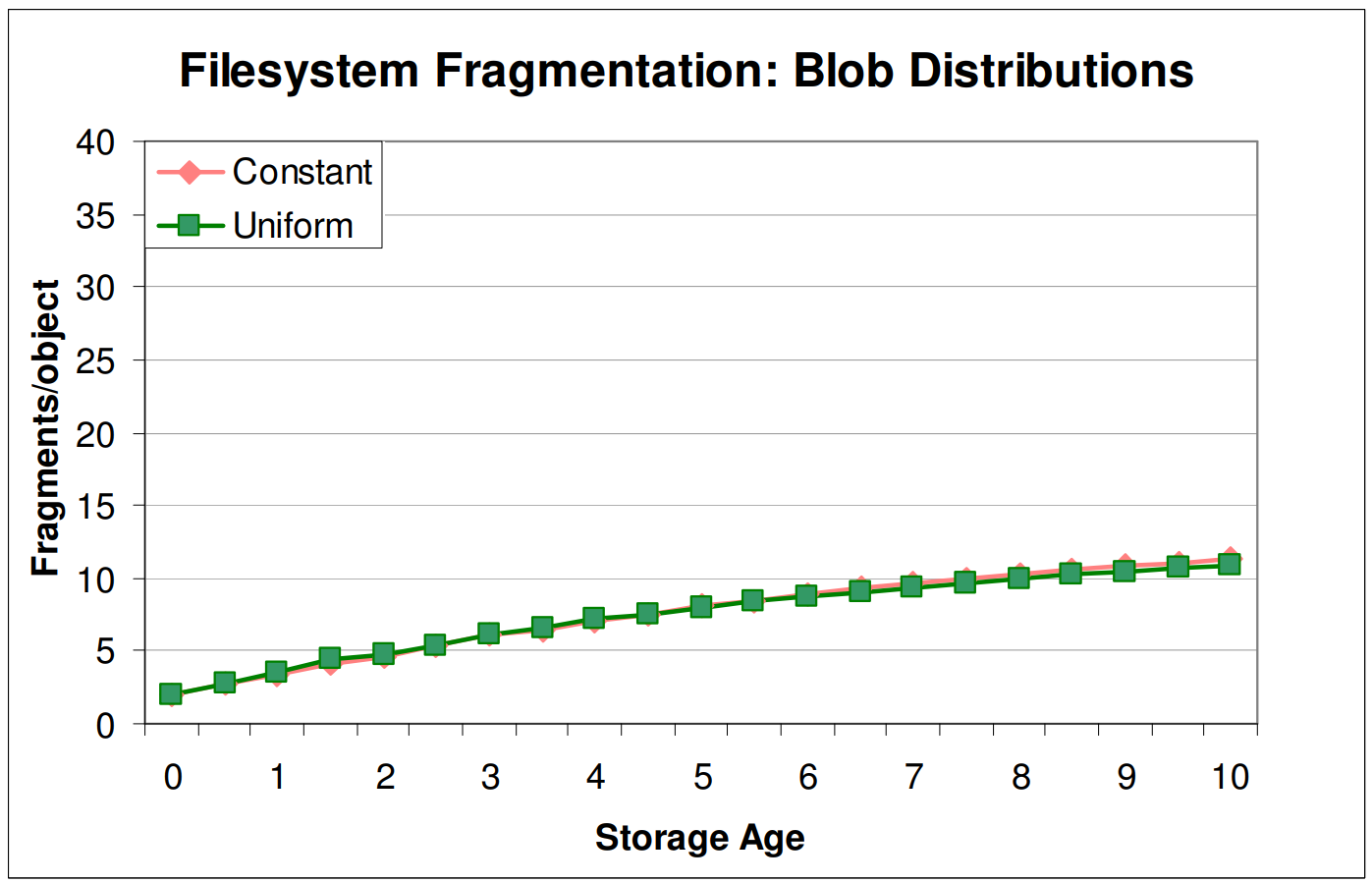
Figure 6은 이에 대한 근거로, constant와 uniform distribution을 갖는 파일들은 동일한 양의 단편화를 발생시켰다. 다만 데이터베이스의 단편화는 시간에 따라 선형적으로 증가하였지만, 파일시스템의 단편화는 그리 크게 증가하지 않는 형태를 보였다.
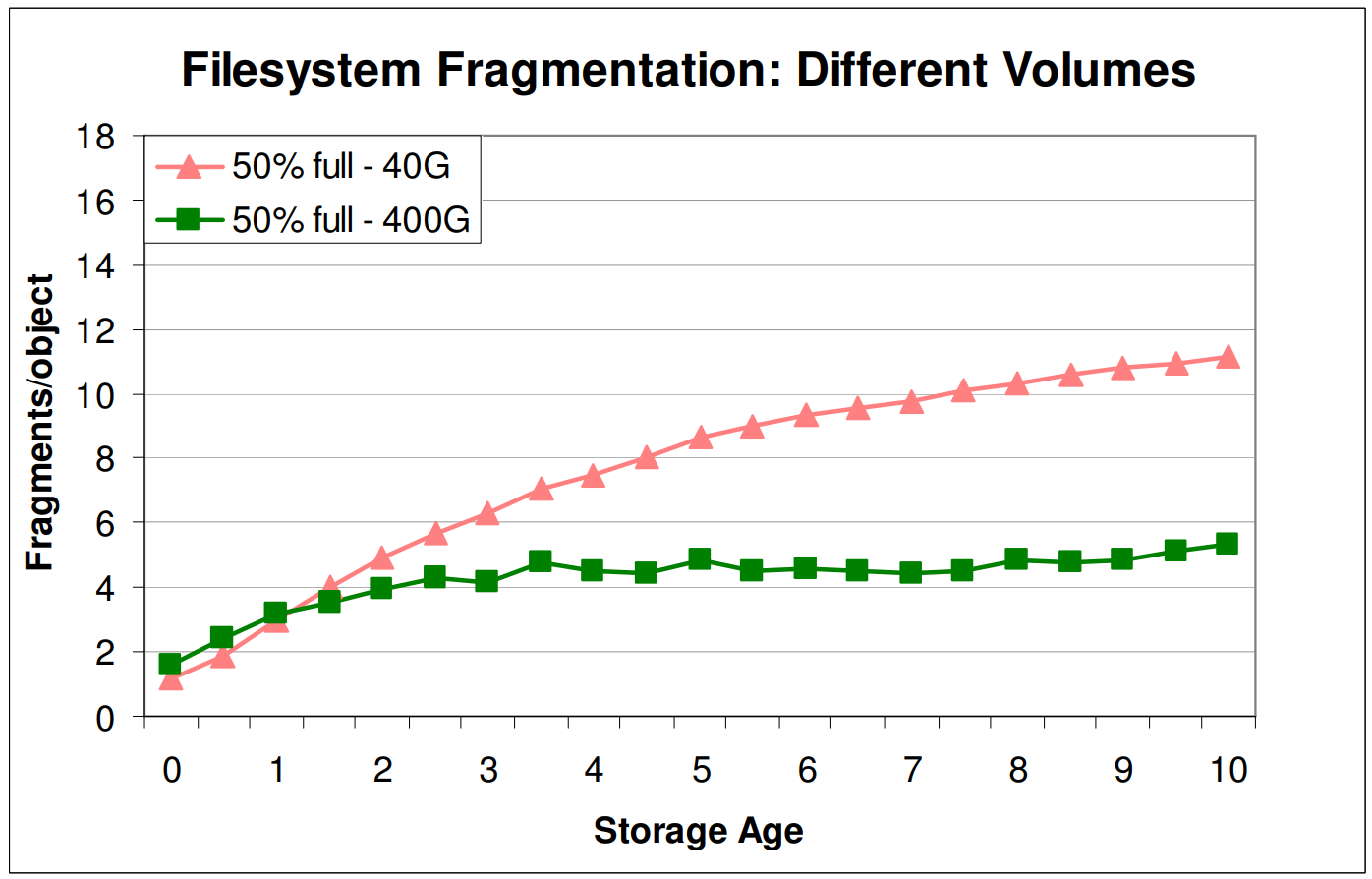
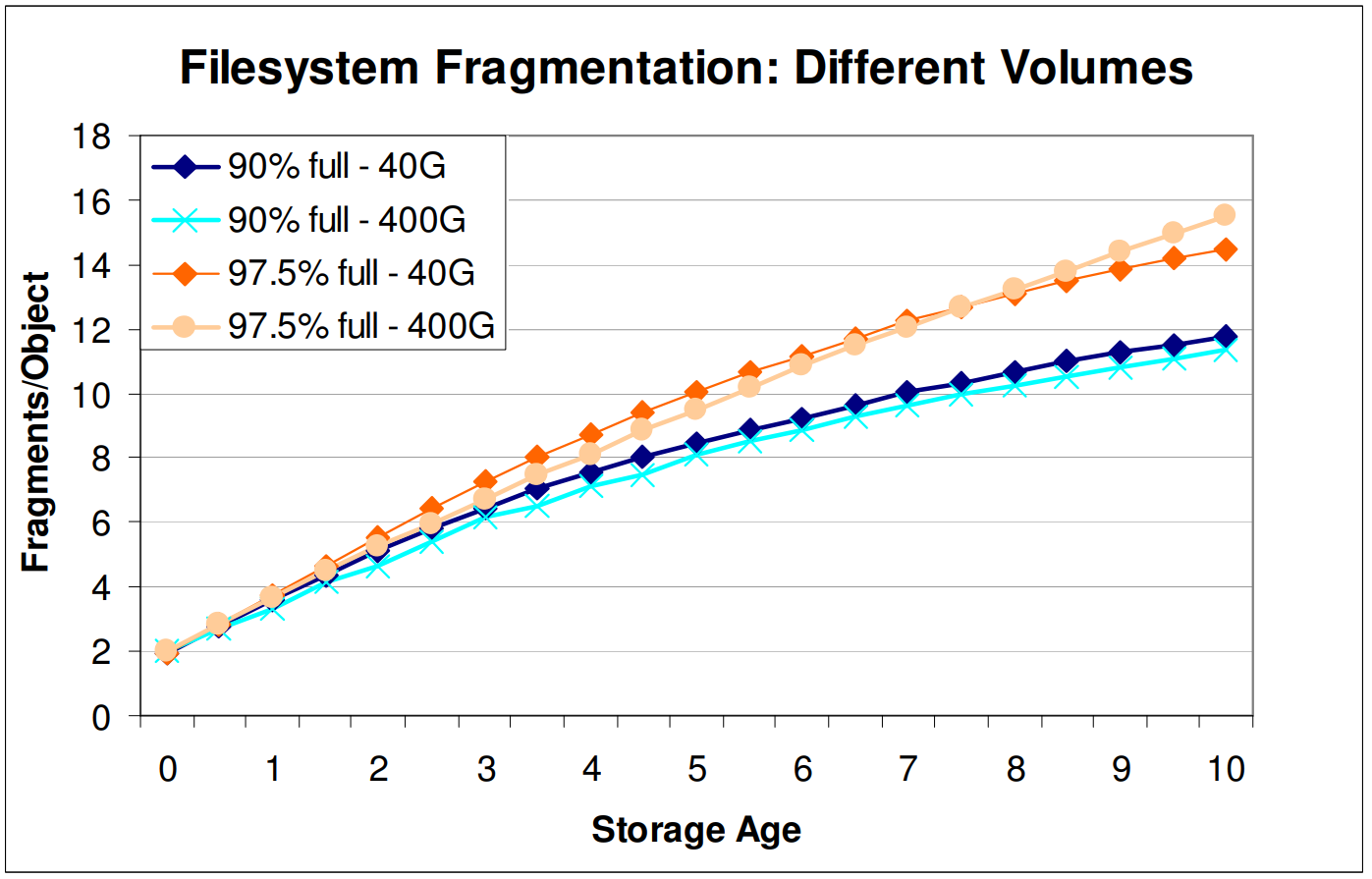
또한 저자들은 디스크의 크기에 따른 단편화도 측정하였다. 디스크의 사용량이 50%일 때 데이터베이스는 디스크의 크기에 관계없이 storage age가 증가함에 따라 단편화가 증가하였지만, 파일시스템에서는 용량이 큰 디스크에서 단편화가 더 작게 발생하였다. 다만 사용량이 더 증가한다면, 디스크 크기가 큰 영향을 미치지 않는다고 하였다.
글을 마치며,
먼저 본인은 컴퓨터 과학 쪽 논문을 정말 오랜만에 읽었다. 석사 졸업 후 시간이 많이 지났으므로 거의 2~3년만인 것 같다. 물론 딥러닝에 관한 논문은 읽을 기회가 많았으므로 아예 손을 놓고 있던 것은 아니지만, 이러한 컴퓨터 성능에 관한 논문은 정말 오랜만인 것 같다. 항상 컴퓨터 과학쪽의 논문은 읽을 때마다 실용적이라는 생각이 드는 것 같다. 당장 이 기술문서만 보더라도 시스템을 설계할 때에 큰 도움을 받지 않았을까라는 생각이 든다.
이 기술문서는 2006년에 발행되었기 때문에 현재의 시스템 설계에 도움을 주기는 힘들 것이라고 생각한다. 다만 이러한 기술문서가 던지는 논리와 메세지는 시스템 설계자에게 큰 intuition을 줄 수 있을 것이라 생각한다. 또, 처음에 이러한 기술문서를 찾아보게 된 계기는 왜 이미지를 DB에 바로저장하지 않고 링크만 저장하는 가에 대한 질문에서 시작되었다. 본인은 충분한 답을 찾았다고 생각한다. 다만 아쉬운 부분은 약 15년 전에 발행된 너무 오래된 기술문서이라는 것이고, 따라서 최신 논문 혹은 기술문서 아니면 article을 찾아봐야 되겠다는 생각이 든다.