UC 버클리에서 주관하는 Full Stack Deep Learning 강의에서 model deploy & monitoring 세션이 있습니다. 강의 내용이 모델 배포 및 모니터링 업무에서 큰 도움이 될 것 같아서 관련 내용을 포스팅할까 합니다. 기본적인 내용이 많지만 나중에 팀원에게 관련 내용에 대해 소개할 때 유용하게 사용할 수 있을 것 같습니다.
프로덕션 환경에서는 수백만의 사용자가 ML 모델을 사용할 수 있습니다. 따라서 여러 사항들을 고려해야 합니다. 먼저 모델 배포 타입에 대해 서술해보면, 모델 배포 타입은 크게 3가지 방법을 고려할 수 있습니다.
- client-side에서 모델을 실행하는 방법(웹브라우저, 모바일 디바이스 등)
- server-side에서 모델을 실행하는 방법
- 서버가 데이터베이스에 접근하여 이미 배치처리된 데이터를 가져오는 경우
Batch prediction

batch prediction은 말 그대로 모델 예측을 배치처리하여 수행하는 것입니다. 현재 수행중인 live 서비스가 이와 같은 경우일 수 있고, 혹은 input과 output이 간단할 경우 DB에 모든 경우의 수를 저장하고 예측하는 사례가 있을 수 있습니다.
장점
- 모델 적용이 간단합니다.
- latency가 비교적 작습니다.
단점
- 복잡한 input에는 맞지 않습니다.
- 유저가 최신의 prediction 값을 얻을 수 없습니다.
- 모델이 자주 stale될 수 있으며, 이를 감지하기 어렵습니다.
Model in Service
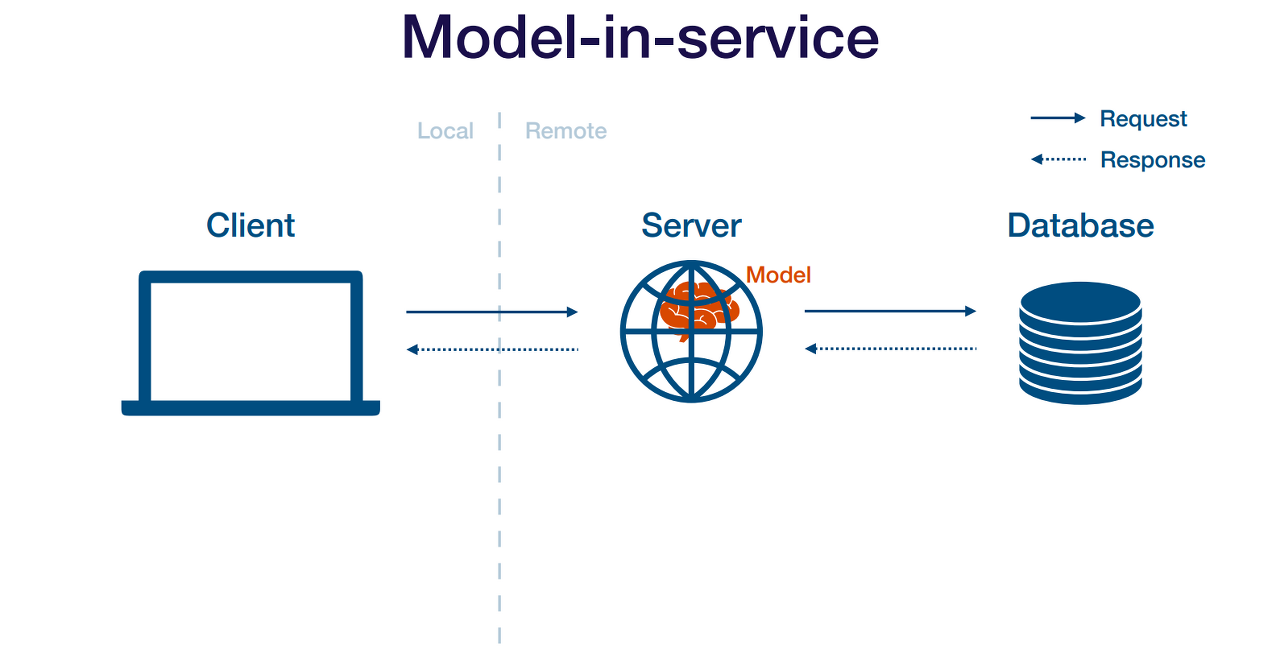
Model in Service 방법은 기존의 웹서버에 모델을 추가하는 것입니다. 따라서 웹서버는 모델을 로드하고 이를 사용해서 prediction을 수행합니다. 이 방법의 장/단점은 아래와 같습니다.
장점
- 기존에 존재하는 인프라를 사용합니다.
단점
- 웹서버는 다른 언어로 작성될 가능성이 큽니다.
- 모델 코드가 서버코드보다 더 빈번히 수정될 것입니다.
- 큰 모델이 존재할 경우 많은 양의 리소스를 점유할 것입니다.
- 서버의 하드웨어가 딥러닝 모델에 최적화되어있지 않을 것입니다(GPU가 없는 경우).
Model As Service

Model As Service 방법은 기존의 웹서버와 모델 서버를 분리하는 것입니다. 따라서 client와 server 모두 모델 서버에 요청할 수 있으며, 모델의 결과를 응답받을 수 있습니다. 이 방법의 장/단점은 아래와 같습니다.
장점
- 웹 서버에 의존적이지 않고, 모델 버그에 의해 웹 앱을 망가뜨릴 가능성이 낮습니다.
- 확장 가능성이 크며, 모델에 맞는 하드웨어를 선택할 수 있습니다.
- 보다 유연한 구조를 갖고 있으며, 많은 어플리케이션에서 모델을 활용할 수 있습니다.
단점
- 추가적인 latency가 발생합니다.
- 인프라 구조가 더 복잡해집니다.
- 모델 서버를 빌드해야 하므로, 추가적인 노동이 필요합니다.
모델 서비스를 위해서는 아래와 같은 사항을 고려해야 합니다.
- REST APIs
- 의존성 관리
- 성능 최적화
- 수평적 확장
- 배포
REST API
- HTTP 통신을 수행할 수 있도록 모델을 REST API 형태로 배포해야 합니다. 대안으로는 gRPC나 GraphQL을 활용할 수 있습니다.
의존성 관리
- 딥러닝 모델을 prediction에는 code, model weight, code dependency(라이브러리 등)가 필요합니다. 세가지 모두 웹서버에 존재해야 하며, code와 model weight는 쉽게 복사할 수 있지만 code dependency는 좀 더 복잡합니다.
- 딥러닝 프레임워크 간 모델 공유를 위해서 ONNX(Open Neural Network Exchange)가 존재한다고 합니다. 아직 사용할 기회가 없어서 사용은 하지 않고 있습니다.
- code dependency는 Docker를 사용해서 해결이 가능합니다.
성능 최적화
- 기본적으로 GPU를 사용할지에 대한 결정이 필요합니다. GPU를 사용하면 높은 throughput을 갖게되는 장점이 존재합니다. 다만 GPU는 set up이 복잡하고 비용이 큽니다.
- CPU만을 사용한다면 멀티스레딩이나 멀티프로세싱을 사용하여야 합니다.
- 성능 최적화의 다른 방법으로는 모델 경량화가 있습니다.
- 자주 입력되는 입력값은 caching하는 것도 좋은 방법 중 하나입니다.
- 혹은 BentoML에서 지원하는 Microbatching 시스템처럼 batch처리하는 것도 좋은 성능 향상 방법입니다.
- 하나의 모델이 GPU 리소스를 모두 사용하지 않는다면, GPU sharing을 하는 것도 좋은 방법입니다.
- 트래픽이 너무 많아지면, k8s같은 시스템을 도입하는 것도 방법입니다.
- 혹은 AWS Lambda와 같은 서버리스 서비스를 사용하는 것도 좋습니다.
Model deployment
- 모델 배포는 단순히 모델 배포만이 아니라, roll out, roll back이 가능해야 하며 모델 파이프라인을 배포하기도 합니다.
Edge Deployment
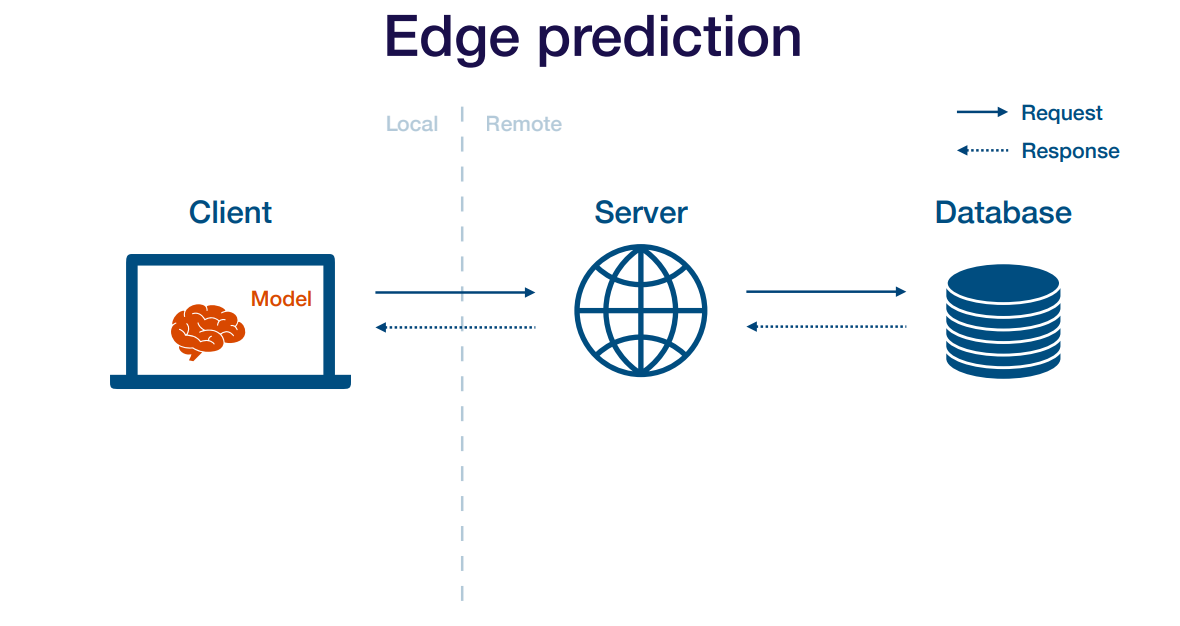
Edge deployment는 서버사이드가아니라 클라이언트 사이드에서 모델을 실행하는 방법입니다. 이 방법의 장단점은 아래와 같습니다.
장점
- latency가 가장 낮습니다.
- 인터넷 연결이 필요하지 않습니다.
- 유저의 디바이스에 데이터가 있기 때문에, 데이터 보안 등의 이슈가 발생하지 않습니다.
단점
- 클라이언트의 하드웨어에서 제약이 발생할 수 있습니다.
- 임베디드나 모바일 프레임워크에서 PyTorch나 Tensorflow가 완전히 지원되지 않을 가능성이 큽니다.
- 모델 업데이트가 힘듭니다.
- 모니터링과 디버깅이 힘듭니다.
모델 모니터링
모델을 배포한 후에는 모델을 모니터링해야합니다. 이는 모델의 정확도 모니터링 뿐만 아니라 입출력 값의 통계 그리고 모델의 기술적인 성능도 포함해야 합니다.
모델 성능 저하
일반적으로 딥러닝은 지도학습이므로, 사용하능한 데이터의 분포에 맞게 함수를 fitting하는 과정을 수행합니다. 하지만 어떤 이유로 인하여 모델 성능 저하가 발생하며, data drift, concept drift 그리고 domain shift가 이에 대한 이유입니다.
- Data drift: 학습환경의 데이터 분포와 프로덕션 환경의 데이터 분포가 다를 경우에 발생합니다. 일반적으로 데이터 파이프라인에 문제가 있었거나, 악의적인 사용자에 의해 발생합니다.
- Concept drift: 유저의 행동이 변했을 경우 발생합니다. 예를 들어, 영화 추천을 하는 경우에 유저의 영화 선택 방식이 변화했을 경우가 있습니다.
- domain shift: 프로덕션 환경에서 아웃라이어가 빈번하게 발생하는 경우 혹은 이에 준하는 데이터 분포가 발생하는 경우입니다. 이는 long tail scenario가 발생할 가능성이 존재합니다.
Data drift의 타입

- 모델이 새로운 도메인에 배포되는 경우
- 혹은 전처리 파이프라인에 버그가 발생한 경우
- 코로나 바이러스처럼 큰 변화가 발생한 경우
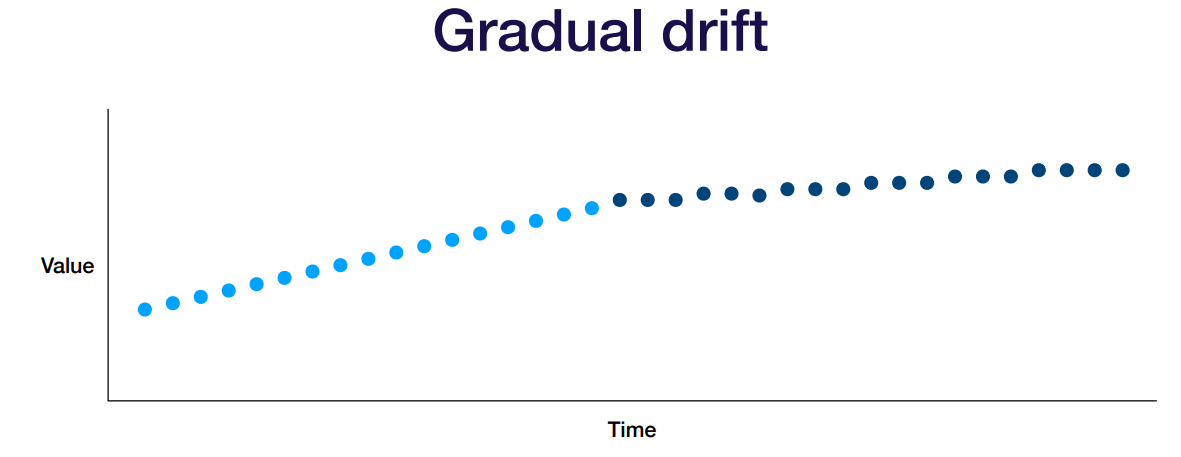
- 유저의 선호도가 시간이 지남에 따라 바뀌는 경우
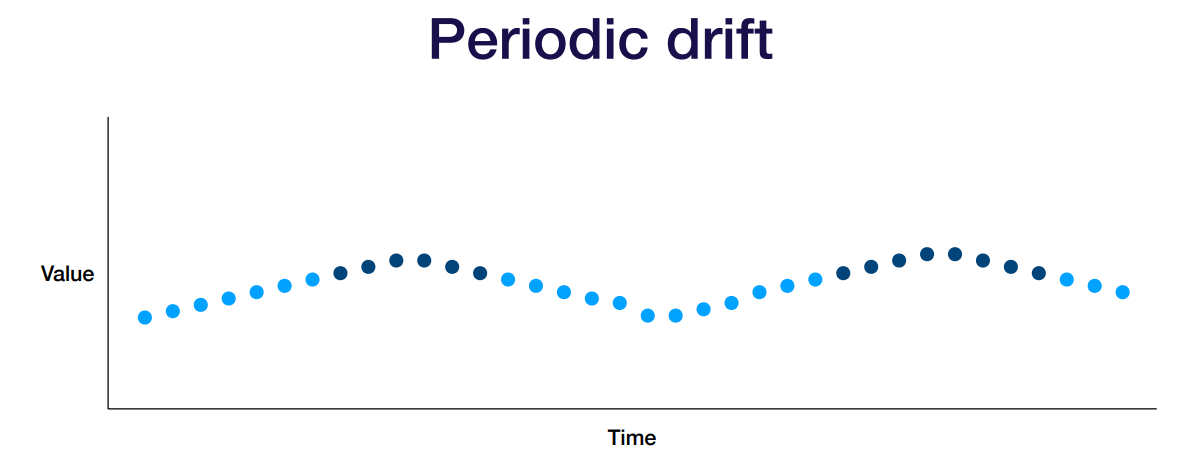
- 유저의 선호도가 seasonal한 경우
- 혹은 다른 시간대의 사용자들이 모델을 사용하는 경우
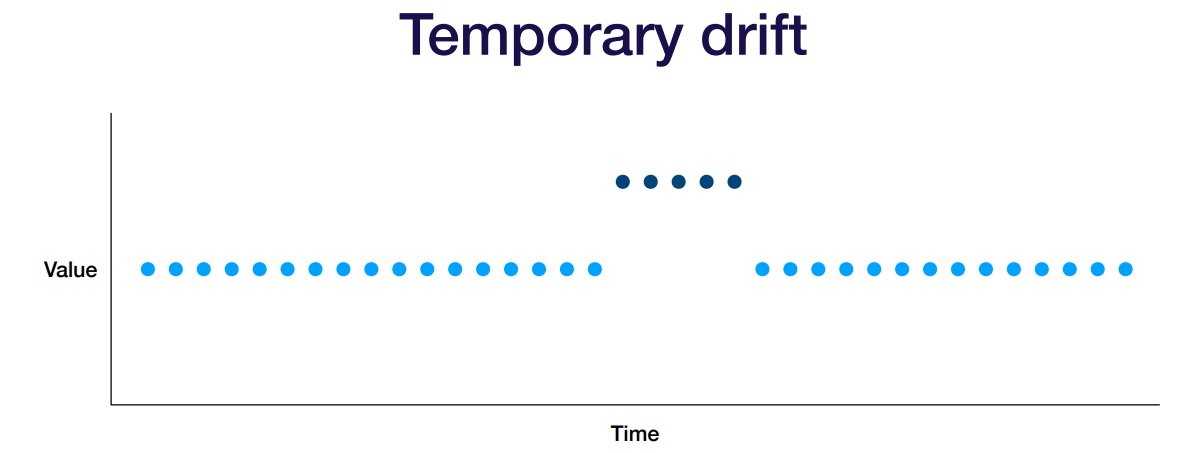
- 악의적인 사용자가 발생한 경우
- 새로운 유저가 다른 의도로 여러 서비스를 사용하는 경우
- 어떤 유저가 의도와 다르게 모델을 사용하는 경우
실제로 어떤 한 글로벌 이커머스 기업은 아래와 같은 버그가 있었다고 합니다.
- 새로운 유저에 대한 데이터를 재학습하지 않은 경우가 발생했습니다.
- 이 버그는 몇주동안 지속되었고, 새로운 유저들은 기존의 추천 시스템이 추천하는 결과를 받았습니다.
- 이로 인해 몇백만 달러의 손실이 발생했다고 합니다.
모니터링 대상
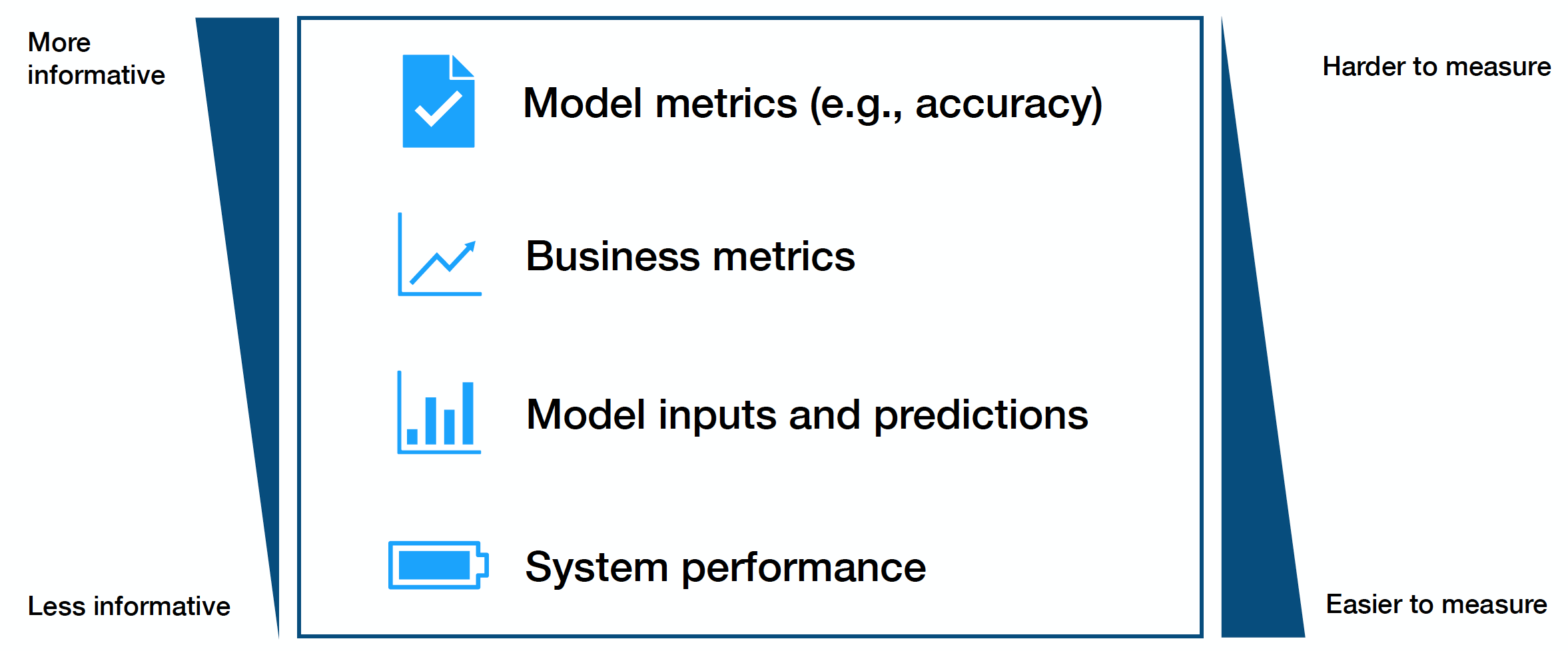
일반적으로 크게 네가지의 정보를 모니터링합니다.
- 가장 어려운 모니터링 대상은 모델 성능 측정이라고 합니다. 실제 프로덕션의 데이터에는 라벨이 없기 때문입니다.
- 비즈니스 메트릭을 모니터링하면 모델 성능 저하를 확인할 수 있을 것이라고 합니다.
- 모델 입력값과 예측값은 가장 간단하면서도 데이터 drift를 확인할 수 있을 것이라고 합니다. 하지만 실제 성능을 측정할 수 있을지에 대한 의문은 있다고 합니다.
- GPU 사용량과 같은 시스템 성능 측정은 심각한 버그를 확인할 수 있는 방법이라고 합니다.
데이터 분포 변화를 탐지할 수 있는 방법
- 프로덕션환경의 데이터와 레퍼런스 데이터를 비교하는 방법이 있을 수 있습니다. 예를 들어 슬라이딩 윈도우 방법을 사용하여 레퍼런스 데이터와 비교할 수 있습니다. 이 때 레퍼런스 데이터는 실제 학습에 사용한 데이터를 사용합니다.
- 데이터 분포 비교는 KL Divergence나 KS Statistics를 사용하는 방법이 있으며, 혹은 간단히 min, max, mean등의 통계를 확인하는 방법도 있습니다.
모니터링 툴
- 시스템 모니터링 툴로는 AWS CloudWatch, datadog 등이 있습니다.
- Data Quality tool로는 Great Expectations, Anomalo, Monte Carlo 등이 있다고 합니다.
- ML monitoring tool로는 Arize, Fiddler, Arthur 등이 있다고 합니다.
'MLOps' 카테고리의 다른 글
| Airflow 기초 사용법 및 DockerOperator (0) | 2022.08.10 |
|---|---|
| NVIDIA Docker 설치 (0) | 2022.08.08 |
| MLFlow 원격 모델 저장소에서 pytorch 모델 로딩 시 에러 (0) | 2022.07.20 |
| MLFlow (0) | 2022.07.04 |